ELT + Airflow + DBT + Liquibase
Early Prototype Version
Project info
Data Engineering & Analysis
Introduction
A brief project description or quote to summarize its goals.
“A refreshed and improved version of my previous ETL project — now following ELT principles. ”
Data Engineering Project (Early Prototype)
Project Status: Early Development Phase
This is an early experimental version of the project to explore key ideas and validate the concept.
Why?
(contains a bit of self-promotion ;) )
As I mentioned in my last micropost Status Update: Leveling Up in Data Engineering, the Google Cloud Developers Meetup inspired me to explore new areas in my data stack. I decided to refresh my knowledge by diving into newer technologies.
I've already read Fundamentals of Data Engineering by Joe Reis and I'm currently reading Designing Data-Intensive Applications by Martin Kleppmann (which, by the way, is more challenging).
I'm also working on labs and have started preparing for the first step toward ✨ Google Cloud certification ✨.
What?
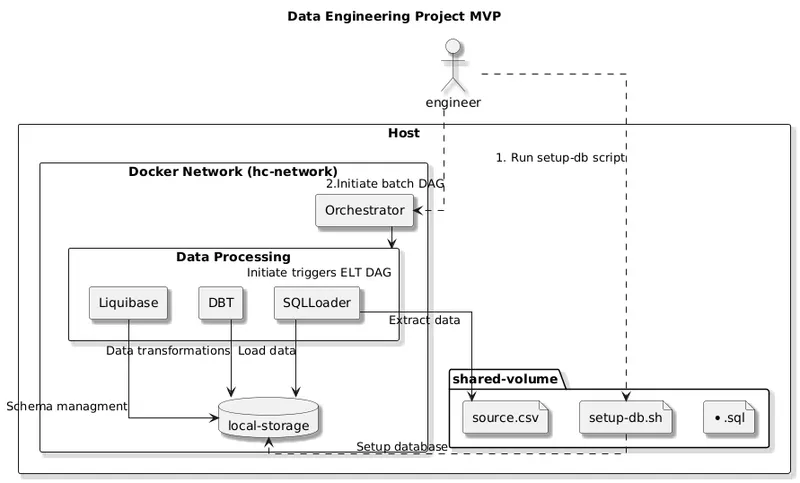
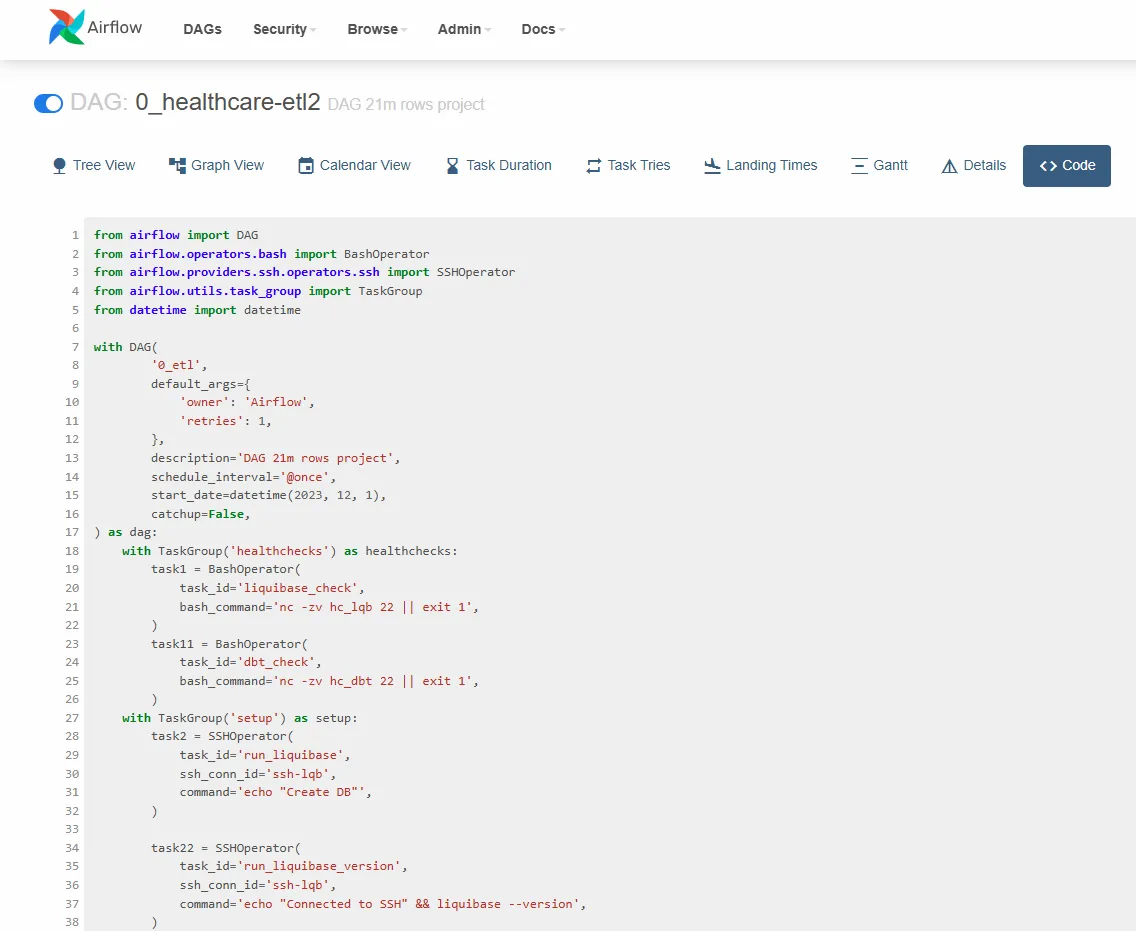
I use Apache Airflow for orchestration, SQLLoader for data extraction and loading from .csv file (dataset dane.gov.pl), and DBT for data transformation (including dimension preloading). Data is stored in Oracle XE, and the environment setup is automated using Debian scripts.
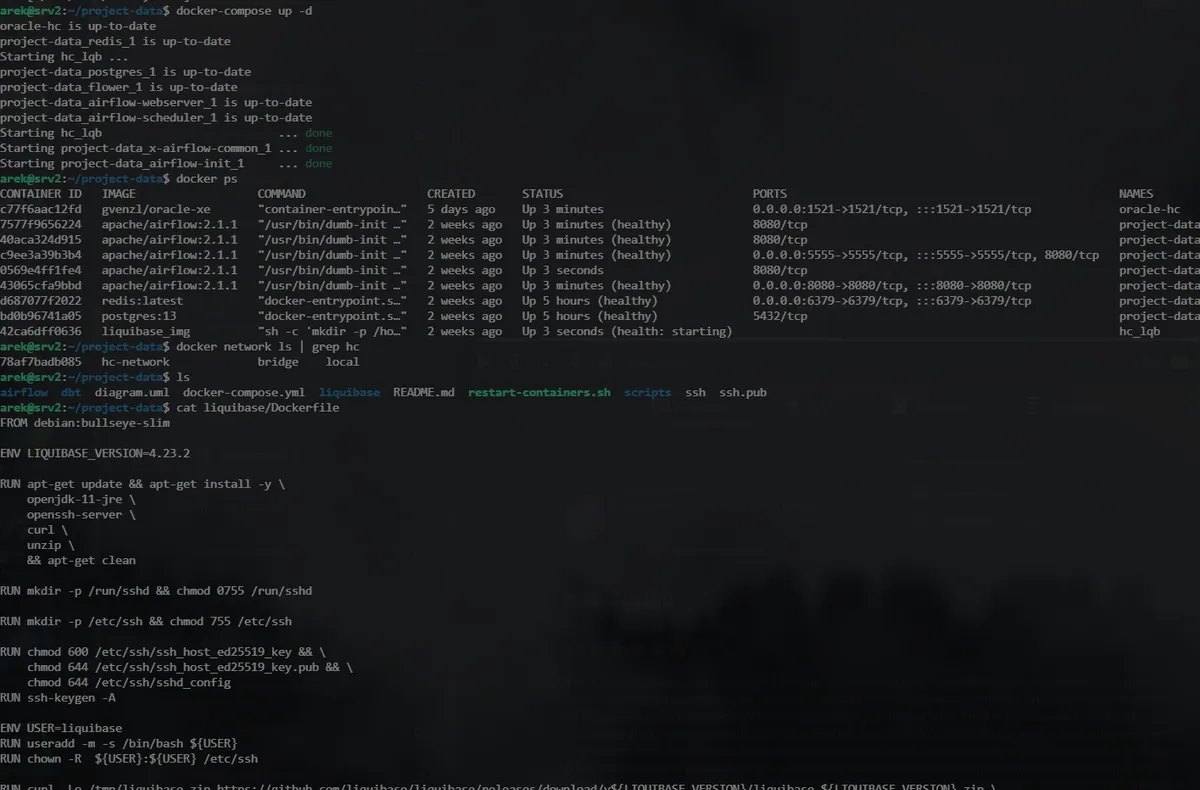
The entire project can be easily run with docker-compose. Key features include:
- A dedicated Docker network to connect services using hostnames instead of IPs.
- The setup builds on Apache Airflow's docker-compose, extended with custom snippets for Oracle XE and a remote Linux host.
- Secure SSH connections are configured using key-based authentication for SSHOperators.
How it works?
TaskSetupDb: Executes bash and SQL scripts to initialize the Oracle pluggable database instance.
TaskExtractLoad: Uses SSHOperator to run commands on a remote Linux host.
- Runs Liquibase to create schemas (raw data, "bronze" stage).
- Loads data using SQLLoader (further optimization and generalization planned).
- Executes DBT models to populate dimension tables.
Todo
Data enginnering todo:
- Implement a more generalized Python-based approach for data loading (considering performance trade-offs vs SQLLoader).
- Explore columnar databases as an alternative for optimized analytics.
- Compare the project's star schema performance against GCP BigQuery using the One Big Table pattern.
- Practice real-time data streaming.
Anlysis todo:
- Use Python visualization libraries for exploratory data analysis (EDA).
- Implement Apache Superset for advanced dashboards and drill-down reports.
Project Overview
In General
Components
Quick Summary
- Data processing
- Storage
- Environment
List of All Technologies
Grouped by Category
| Category | Technologies |
|---|---|
| Orchestration | Apache Airflow |
| DAG | SSHOperator ✦ PythonOperator |
| Data Transformation | DBT |
| Extraction & Load | Bash script ✦ SQL script ✦ SQLLoader |
| Database Change Management | Liquibase |
| Data Source files | .csv |
| RDBMS | Oracle DB 21 |
| Linux | Debian ✦ bash |
| Docker | docker-compose ✦ dockerfile |
Components Specification
Detailed Information Grouped by Components
Table of Contents:
- Data processing
- Storage
- Environment
Details
-
Data processing
Extract, Load, Tranform tools
Tech Stack
Category Description Orchestration Apache Airflow DAG SSHOperator DAG PythonOperator Data Transformation DBT Extraction & Load Bash script Extraction & Load SQL script Extraction & Load SQLLoader Database Change Management Liquibase -
Storage
Source of data. Staging. Target storage.
Tech Stack
Category Description Data Source files .csv RDBMS Oracle DB 21 -
Environment
Operations services
Tech Stack
Category Description Linux Debian Linux bash Docker docker-compose Docker dockerfile
Data Sources
- Dane.gov.pl: 'Dane dotyczące hospitalizacji rozliczonych JGP w latach 2019-2021 (contains hospitalizations 2017, 2018)'. Link. Quantity: >20M.
- Dane.gov.pl: 'Dane dotyczące hospitalizacji rozliczonych JGP w latach 2022'. Link. Quantity: >20M (whole dataset).
- CEZ Polish HL7 Impl.: Discharge and admision modes. Link. Quantity: ~10.
Additional Information
- Domain: Data Engineering
- Status: in_progress
- Keywords: DataEngineering Docker-compose dbt ApacheAirflow ELT bash python
Thumbnail